

Apache Kafka — это мощная платформа для потоковой обработки данных в реальном времени. Её ключевые особенности — высокая производительность, отказоустойчивость и масштабируемость, которые обеспечивают её популярность в построении современных систем обработки событий и аналитики данных.
Принципы работы Kafka
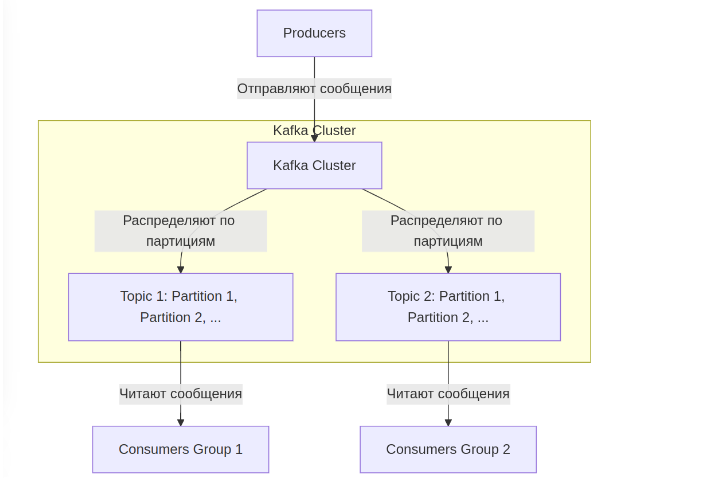
Kafka работает на основе кластерной архитектуры, где несколько машин (брокеров) объединяются в кластер. Данные организуются в топики, которые делятся на партиции. Каждая партиция упорядочена, и сообщения в ней имеют уникальные смещения (offsets).
Топики и партиции: основная единица хранения данных. Топики делятся на партиции, что позволяет обрабатывать данные параллельно. Партиция — это упорядоченный лог файлов, хранящий сообщения. Каждое сообщение в партиции имеет уникальный идентификатор (offset), что позволяет клиентам отслеживать и управлять чтением данных.
Производители (Producers): отправляют данные в топики. Производитель может выбрать конкретную партицию для отправки.
Потребители (Consumers): читают данные из топиков, поддерживая группы для распределения нагрузки.
Репликация: для обеспечения отказоустойчивости данные в партициях реплицируются на несколько брокеров.
Offset (смещение)
Каждое сообщение в партиции Kafka имеет уникальный идентификатор — смещение (offset). Это последовательный номер, который указывает на позицию сообщения в пределах конкретной партиции. Offset играет важную роль в обработке данных, так как позволяет потребителям:
1. Отслеживать прогресс обработки сообщений
Потребитель сохраняет текущее смещение для каждой партиции, чтобы продолжить чтение с того места, где он остановился, даже после перезапуска.
2. Повторное чтение данных
Kafka сохраняет сообщения в течение заданного времени. Зная offset, потребитель может заново прочитать ранее обработанные сообщения.
3. Обеспечение последовательности
Используя offset, Kafka гарантирует, что сообщения из одной партиции обрабатываются строго в порядке их записи.
Хранение и время жизни сообщений
Сообщения в Kafka сохраняются на диске для устойчивости и доступны для повторного чтения в течение заданного времени, например, 7 дней (по умолчанию). Время хранения сообщений можно настроить через параметры, такие как log.retention.ms или ограничить объёмом дискового пространства через log.retention.bytes
Высокая производительность Kafka
Kafka достигает высокой производительности благодаря следующим аспектам:
1.Использование дисковой памяти: Вместо оперативной памяти Kafka хранит сообщения на дисках. Благодаря последовательной записи и чтению данные обрабатываются с минимальной задержкой.
2.Оптимизация ввода-вывода: Kafka применяет техники, такие как batch processing (пакетная обработка) и zero-copy (передача данных напрямую из буфера в сеть), что минимизирует задержки.
3.Горизонтальное масштабирование: Разделение данных на партиции позволяет добавлять новые брокеры для распределения нагрузки.
4.Минимальная сериализация: Используются компактные бинарные форматы данных, такие как Avro или Protobuf, что снижает расходы на обработку.
5.Кэширование страниц: Операционная система кэширует часто запрашиваемые данные, что ускоряет доступ.
Теперь рассмотрим использование Kafka в Laravel на практике.
Использование Apache Kafka в Laravel
Установка и настройка
Для начала установите пакет:
composer require mateusjunges/laravel-kafka
Зарегистрируйте сервис-провайдер в config/app.php
'providers' => [
...
Junges\Kafka\Providers\LaravelKafkaServiceProvider::class,
],
Опубликуйте файл конфигурации
php artisan vendor:publish --provider="Junges\Kafka\Providers\LaravelKafkaServiceProvider"
Пример файла
config/kafka.php:
return [
'bootstrap_servers' => env('KAFKA_BOOTSTRAP_SERVERS', 'kafka:9092'),
'topics' => [
'test-topic' => [
'num_partitions' => 1, // Количество партиций для топика
'replication_factor' => 1, // Количество реплик для каждой партиции
],
],
];
Отправка сообщений
Пример отправки сообщений в топик topic-order в контроллере OrderController:
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use Junges\Kafka\Facades\Kafka;
use Log;
class OrderController extends Controller
{
public function save(Request $request)
{
// ...тут может быть сохранение данных заказа...
try {
Kafka::publish()
->onTopic('topic-order')
->withBodyKey('key-order', $order)
->withHeaders(['my-header' => 'my-text-header'])
->send();
} catch (\Exception $e) {
Log::error('Ошибка публикации сообщения: ' . $e->getMessage());
}
return response()->json(['message' => 'Заказ успешно оформлен'], 201);
}
}
Использование ключей:
Ключ сообщения (key-order) определяет, в какую партицию топика будет отправлено сообщение. Это полезно для обеспечения порядка обработки данных. Например, если все сообщения, связанные с конкретным пользователем, имеют одинаковый ключ, Kafka гарантирует, что они будут записаны в одну партицию и обработаны последовательно.
Типы данных в Kafka
Kafka поддерживает различные типы данных для сообщений:
1. Строки: Простейший и наиболее распространённый формат, часто используемый для текстовой информации.
2. JSON: Удобен для обмена структурированными данными между системами.
3. Avro: Популярный двоичный формат с компактным размером и поддержкой схем, что позволяет эффективно управлять структурой данных.
4. Protobu: Ещё один двоичный формат с высокой производительностью и удобной сериализацией.
5. Любой двоичный формат: Kafka не накладывает ограничений на формат данных, так как сообщения хранятся в виде последовательности байтов.
Выбор типа данных зависит от требований проекта, таких как производительность, читаемость и размер данных.
Для преобразования в нужные типы можно использовать методы usingSerializer, (например...
...->usingSerializer(new MyCustomSerializer()) ) и usingDeserializer (->usingDeserializer(new MyCustomDeserializer()))
Получение сообщений
Создайте команду для обработки сообщений:
php artisan make:command ConsumeKafkaMessages
Пример команды ConsumeKafkaMessages
namespace App\Console\Commands;
use Illuminate\Console\Command;
use Junges\Kafka\Facades\Kafka;
use App\Consumers\ProcessMessageConsumer;
class ConsumeKafkaMessages extends Command
{
protected $signature = 'kafka:consume';
protected $description = 'Consume messages from Kafka topics';
public function handle()
{
Kafka::consumer(['topic-order'])
->withConsumerGroupId('order-group') // Указываем группу потребителей
->withHandler(new ProcessMessageConsumer)
->build()
->consume();
}
}
Создайте обработчик сообщений ProcessMessageConsumer:
namespace App\Consumers;
use Junges\Kafka\Contracts\ConsumerMessage;
class ProcessMessageConsumer
{
public function __invoke(ConsumerMessage $message): void
{
logger()->info('Получено сообщение.');
logger()->info('Headers: ', $message->getHeaders());
logger()->info('Body: ', $message->getBody());
logger()->info('Timestamp: ' . $message->getTimestamp());
}
}
Запустите команду для обработки сообщений:
php artisan kafka:consume
Группа потребителей:
Группа потребителей в Kafka позволяет масштабировать обработку сообщений. Если у вас несколько экземпляров приложения, подключённых к одной группе, Kafka распределяет партиции топика между потребителями группы. Это даёт следующие преимущества:
1. Масштабирование: Если у топика 3 партиции и вы запускаете 3 потребителя в одной группе, каждая партиция будет обрабатываться одним из них, ускоряя обработку.
2. Повторное подключение: Если один из потребителей отключится, Kafka перераспределит партиции между оставшимися в группе, обеспечивая отказоустойчивость.
3. Уникальная обработка: Каждое сообщение из партиции обрабатывается только одним потребителем в группе, что исключает дублирование.
Если же каждый потребитель принадлежит своей группе, они будут получать все сообщения из топика независимо от других. Это полезно для задач, где данные нужно обработать несколькими системами параллельно.
Заключение
Apache Kafka обеспечивает высокую производительность, отказоустойчивость и масштабируемость за счёт архитектурных решений и оптимизаций. Используя пакет mateusjunges/laravel-kafka, можно легко интегрировать Kafka в проекты на Laravel, отправляя и получая сообщения с минимальными усилиями.
